入手iphone X後,前幾天開始好奇是不是可以來玩些什麼,於是去翻翻關於臉部追蹤的資料庫,發現蘋果對於這塊的API寫得很好,可以輕鬆取得相關追蹤資訊。於是就研究了些方法,讓資料可以帶到Houdini。
紀錄一下這幾天研究的一些心得。
前言
上面的影片是用擷取好的資料在houdini重現,另外將捕捉時的圖像序列存下來,放在旁邊對照,造成有些人誤會是即時的。
但的確有另外做即時串流的捕捉模式,如下圖範例,不過就沒有辦法串流圖像,可以看到臉部生硬很多。(格率不夠是quicktime擷取4K螢幕的問題,手機APP跟伺服器當下是每秒60格運作的)
先附上這次的GitHub原始碼,程式基礎很淺,有點亂請見諒。
整體的流程,分客戶端跟伺服器端:
- 客戶端:在iphone X上寫一個APP,可以將臉部的追蹤資訊以串流送出或者儲存在手機。
- 伺服器端:在houdini上讀取資料,串流模式下架設伺服器接收臉部資訊封包,並將資料轉換成動態。
客戶端(iPhone, Swift)
概要
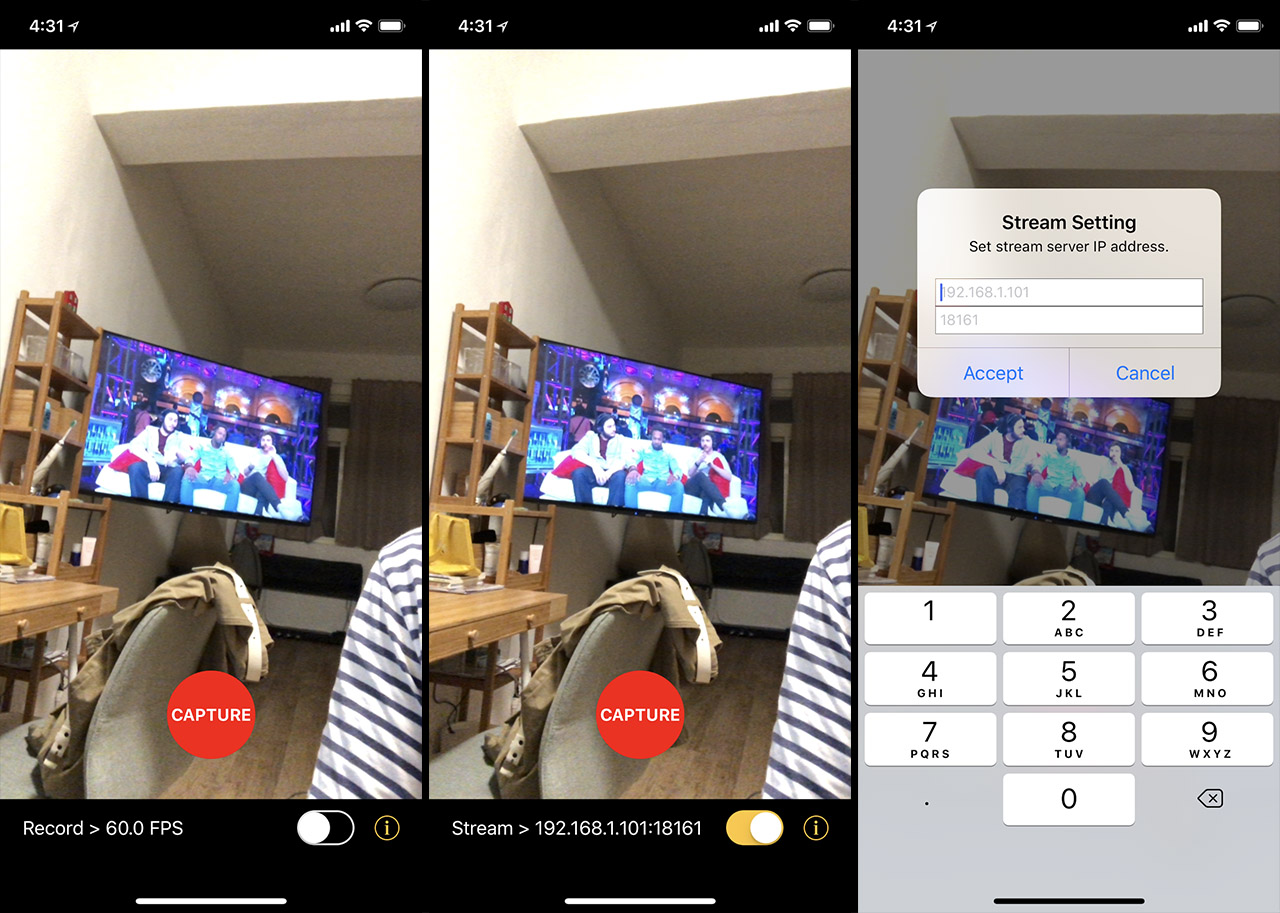
陽春的介面:錄製模式、串流模式、細節設定,和一顆錄製Capture按鈕
臉部追蹤的部分是用到ARKit(連接SceneKit),這邊蘋果已經幫我們準備得非常完善,追蹤運算那些深層都不用管,只要拿結果資料就好。
ARKit的細節就不詳述了,網路上有非常多文章寫得不錯,WWDC2017也有很多長知識的影片。現在相關文章大多都是一般的場景AR,而不是關於臉部的AR,不過大同小異,基礎的架構是一致的,蘋果研發網站的文件相當齊全,也有範例檔案跟說明,幾小時就能上手。
接下來所說的大部分在GitHub的程式碼都有註解,不再多做贅述。
客戶端這邊的流程是:
從AR框架取得資訊 -> 將資訊整理 -> 看是要串流封包給伺服器還是存檔在應用程式資料夾
要取得的有:臉部頂點資訊、臉部transform、臉部blendshape資料、攝影機transform、攝影機圖像
臉部頂點資訊
ARKit主要的追蹤資料是存在ARSession.currentFrame裡面,也就是目前當格的追蹤資訊(ARSession預設捕捉是每秒60格),臉部追蹤時只會有一個ARAnchor,如果畫面有兩個臉也只會針對比較明顯的去做追蹤, 而臉部的ARAnchor有一個專屬繼承類別叫ARFaceAnchor,就存有臉部模型與頂點位置資訊,用ARFaceAnchor.geometry.vertices可取出向量陣列。
臉部transform
方才只有臉部頂點的資訊,類似表情這樣(像這影片),那還需要旋轉位移等資訊才能移動頭部,同上從ARAnchor.transform拿到matrix4資訊。
臉部blendshape
除了頂點資訊來做表情,還有更原生的blendshape資料可以拿,詳細的blendshape列表可以查看蘋果研發網站,還會有圖片清楚示意每個blendshape的morph。這個資料一樣要從ARFaceAnchor.blendShapes取得(得到的類型是字典)。
攝影機transform
跟臉部一樣,是matrix4,這個攝影機資訊拿到是要在houdini裡面做投影貼圖用,結合待會要說的攝影機圖像。ARSession.currentFrame.camera可以拿到ARCamera,就是追蹤環境下當格的攝影機資料(還有追蹤狀況品質等),再從ARCamera.transform取得位移。
攝影機圖像
從ARSession.currentFrame.captureImage得到當格追蹤參考的圖像,解析度是1280x720,比較要注意的是取得的型態是YUV的CVPixelBuffer,要存成JPG或PNG需要再進行一些步驟,寫在GitHub原始檔的Extensions.swift裡。
取得資訊後,要轉換成字串以便寫成檔案或串流,詳細的方法也寫在Extension.swift裡,就是很陽春的轉成字串並分隔,時間格由每行分開,每種資料之間由”~”分開,資料自己再以”:”分開。
浮點數包含”e”這種的轉成字串沒有關係,houdini是可以轉回去的,blendshape資訊也是如此。
取得資訊、資訊轉成字串都好了,接下來是輸出。
分成兩類:Record錄製、Stream串流
Record錄製
錄製比較需要的是可以自訂FPS,用Timer.scheduledTimer去做到這點。
錄製的流程是:每次執行捕捉時都將資料暫存陣列,而攝影機圖像就先存成JPG。錄製完後,將捕捉暫存陣列轉換成字串寫成txt文字檔,跟方才陸續存成的圖像序列都放在APP下documentary建立資料夾打包。
每格的圖像處理是另外的queue去跑,主執行還是跑捕捉,只是會把圖像資料丟給這個queue,queue再自行轉成jpg跟寫檔,queue在執行這過程要再包一個autoreleasepool,不包的話,跑UIImageJPEGRepresentation會讓記憶體瞬間衝滿,不會釋放。
錄製的檔案以錄製時間分類資料夾,從itunes可以輕易取出
Stream串流
串流這塊很棘手,其實這幾天研究下來有絕大部分的時間都在處理這塊,對於網路和檔案傳送這塊不是很了解。
跟錄製從Timer.scheduledTimer執行不一樣的是,串流是由ARSession的delegate:didupdate來執行,也就是捕捉的每格都會串流,來做到最即時的反應。
用Stream.getStreamsToHost取得outputStream連接伺服器端,再將取得的資料轉成字串輸出,而每格的總執行時間要低於0.016秒,才能穩定60格輸出。當然還有傳的資料最後加上結尾字符,跟出錯時提醒伺服器停止接收等必須動作。
至於圖像的串流目前能力還做不到。
伺服器端(Houdini, Python, Vex)
概要
伺服器端完全在houdini裡面搭建,先建立整體架構,用Python SOP匯入錄製資料,串流部分則利用hou.session(python source editor)完成接收伺服器的編寫。
blendshape資訊在這流程下其實沒有用到,只是提供一個取出來的方法,以供之後有搭配rig的角色使用。
整體節點如下圖所示:
由讀取臉部模型的faceGeo當起始,以Record錄製跟Stream串流兩種模式來分成兩大區塊。
faceGeo
讀取一個臉部模型的bgeo.sc檔案(GitHub有附),這是利用Xcode擷取出Scenekit的Collada檔案轉換而來,也就是ARFaceGeometry的模型。目前還不知道怎麼利用Model I/O匯出模型,既然臉部頂點都一樣,都是用同一個拓樸去貼合臉型,就沒必要每次都擷取模型。
Record Mode區塊
material
上一個unlit材質,並上臉部貼圖,材質的貼圖路徑是跟getRecordData連動的(去取得該路徑資料夾下的臉部圖像序列)。
getRecordData
Python Sop,這區塊的核心,選擇錄製資訊的資料夾,之後都幫你轉換好。滿意外的是貌似只讀取一次文字檔,之後拖曳時間軸順暢沒壓力,也不會有重複硬碟讀取。
這邊是去抓指定資料夾裡的faceData.txt,並將資料解析給各頂點設定位置,然後將攝影機跟臉部的transform跟blendshapes給放到detail屬性裡。
houdini 16.5新增的選擇資料夾parm,突破以往只能選檔案的限制,也使得這個hip只能用16.5開啟。
vex_faceAni
然後將已經移動完位置的頂點套上臉部matrix資訊。
vex_camTrans
將攝影機的matrix解出位移跟旋轉,其實AR攝影機只會有旋轉的資訊。這個資訊會套在根路徑的投影貼圖專用攝影機。
vex_projectUV
投影貼圖的攝影機套上位移後,取得攝影機跟頂點的相對位置,投影成頂點的uv。這樣錄製的部分就完成了。
Stream Mode區塊
useMapping
因為串流模式沒有串流貼圖,可以先用錄製模式取得的某格貼圖跟uv去上在模型上。
streamServer
這區塊的核心,伺服器IP設定、開關控制,以及用接收的資訊去驅動模型。
在這邊新增按鈕,跟hou.session做連動控制伺服器的開關跟設定IP,並有一個隱藏的字串parm("datas")去接受串流得到的捕捉資訊,code的wrangle部分再用這個parm("datas")去移動頂點。
hou.session module
跟iPhone X 串流溝通的部分是寫在這裡,也就是存在hip本身裡面的python檔,將公式定義在這裡,方便修改以及跟streamServer節點的按鈕連動。
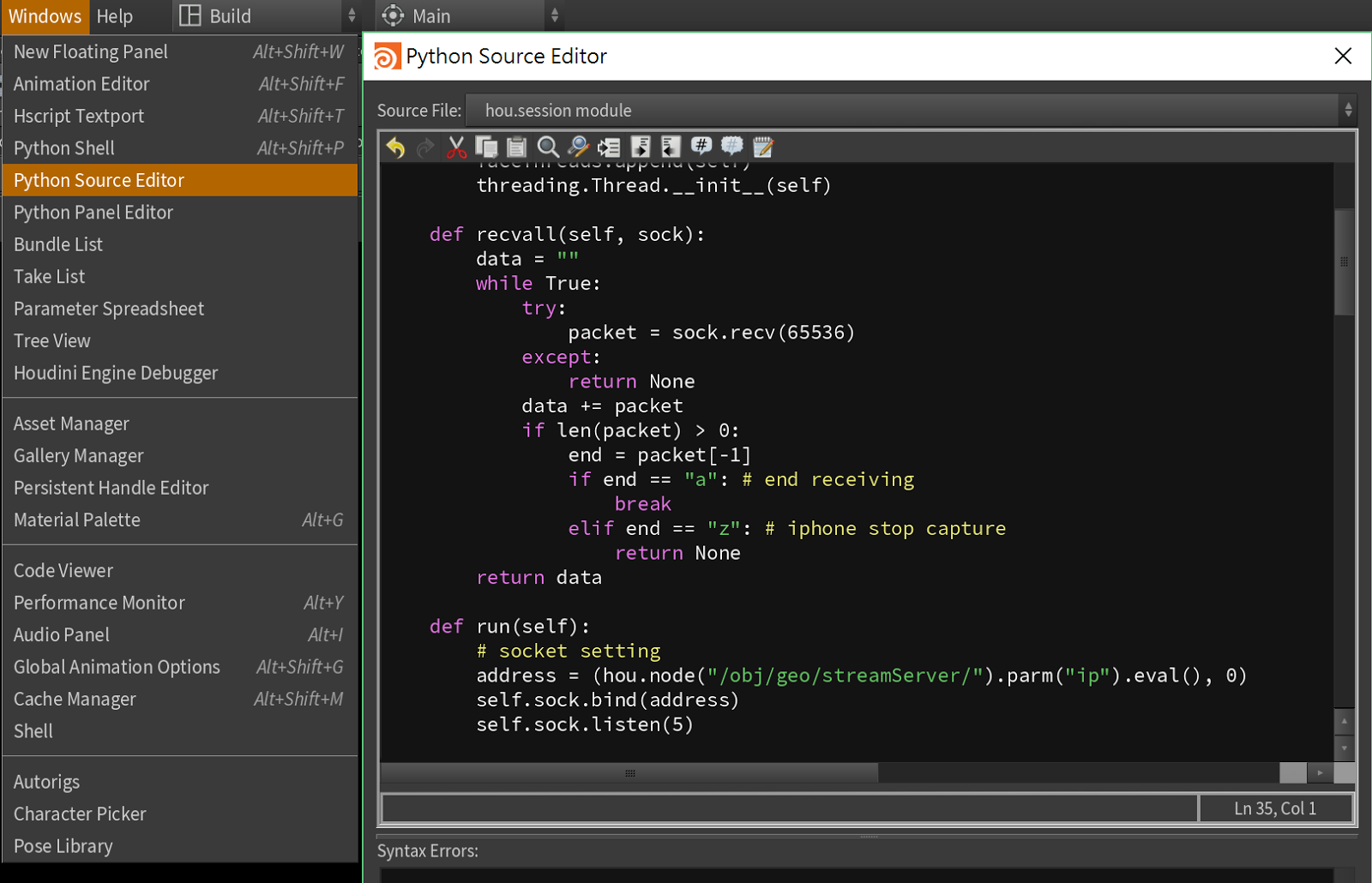
接收的伺服器制定了兩個執行緒,一個執行緒持續接收iPhone X這邊的封包,並將接收好的封包丟在一個queue,另一個執行緒持續等著這個queue,這個queue一有東西便馬上拿出來放到streamServer的parm("datas")裡。
這邊兩個執行緒都會持續播報每秒執行的資料數量,正常來說應該都要是print 60, 60,而houdini viewport更新的部分可能礙於顯示效能,會是30~60fps跑。
伺服器端的部分大抵是這樣,其實東西都很簡單,但學習串流的部分花了很多時間,到目前為止其實都還不算穩定,有時候也會因不明原因延遲,要重新接幾次才會順暢60格跑。至於圖像串流,曾經試過將圖像轉成jpg後用base64方式去傳,但都會略高於1/60秒的處理時間,更何況還有houdini這邊圖像更新所需的時間,還是將這種事情留給unreal或者unity做吧。