為了增加碎裂的細節通常會用particle模擬一層debris,再用簡單的幾何形狀去copy。不過如果後端算圖是要給Maya或Max,出alembic交接的話,會是非常龐大的資料量。
這邊介紹一下兩種研究出來的方法。
方法A
第一種是只適合在max使用容量最小的方法,需要使用Frost。
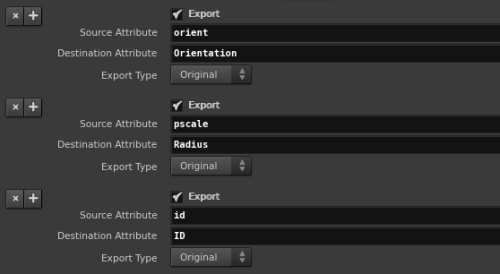
先將particle匯出prt ,這邊是以國外強者維護編譯的ROP來執行,要把orient、pscale、id的attribute名稱對映到prt可讀的Orientation、Radius跟ID。
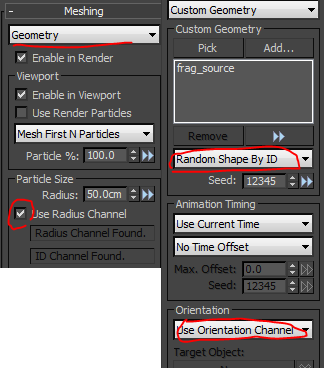
在max裡匯入prt,可以直接在frost裡讀particle檔案,但通常我會創一個prt loader去讀取以便再上magma修改。
只要有Radius跟Orientation通道,再把houdini的碎塊讀進來當custom geometry的source,就可以省下很多資料量達到跟houdini的copy一樣的效果。另外如果custom geometry不只一個,記得要勾選random id,不然採樣模型動起來會閃爍不固定。
方法B
之前有介紹過一種快速輸出point cache的方法,這種方法等於我們只要存一格完整資訊的debris,再用只紀錄頂點位置的point cache去形變即可,容量也是不大。
但這邊有一個非常大的問題:point cache只能相容固定頂點數的模型。
像debris這種particle生成隨時間增加數量的物件,不可能每格一樣多,所以基本上不能使用這種方法。
不過,debris也有一種特性:一旦生成就不會消失,數量只會遞增。
所以我們可以取最後一格的particle當sample,這一格有所有其他格的particle,以id的屬性來跟前面格數一一比對,前面格數沒有的id,就全部生成補上去,然後保存下來,便可以達成全部格數一致,也不會被看見。
這種方法,用python比vex方便很多,所以在這邊就新增一個python sop。
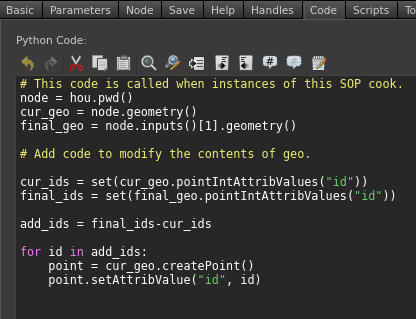
用python的set很輕易地就可以取出每一格沒有的point補上去,因為這邊除了id要特別指定之外 ,大部分attribute預設就是0,scale也會是0不會被看見,就不用再另外指定數值。通過這個python sop,particle數量就一致了,接著處理要instance的碎片部分。
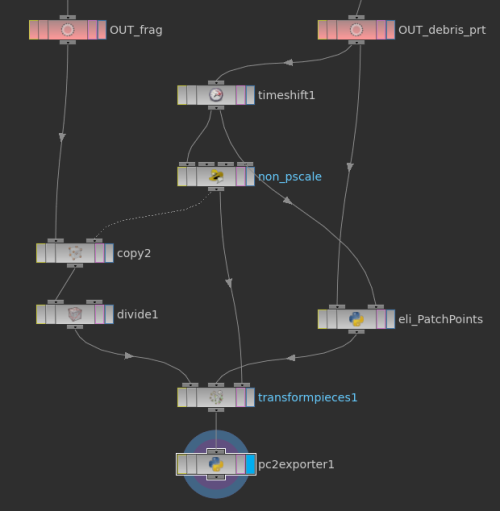
要將碎片複製成與particle一樣數量後,用transform pieces結合起來,如同packed rbd的模擬一樣。首先,碎片先自行經過一次copy,copy的資訊記得要帶上id給primitive,通常還會stamp這id去random每個碎片的旋轉,這邊值得注意的是這copy之前,採樣points的pscale要先全部設為1基準值,並採用最後一格的時間,待會的transform才會正確。複製完後,再把這兩者transform pieces藉由id結合起來,transform pieces的rest points輸入點一定要再接一次剛剛複製用的採樣points,到這邊就可以得到一個跟平常copy方法完全一模一樣位移旋轉的碎塊,卻有固定頂點數。接下來用之前的PC2出法再外加單格fbx,時間跟容量都節省相當多。
以上如果是要匯給max已經作業完成,但如果要給maya,還要把pc2轉換成maya的pointcache檔。
轉換方法很簡單,開啟maya的mel輸入以下指令即可。
cacheFile -pc2 1 -pcf “X:/path/debris.pc2” -dir “X:/output_path/” -format “OneFile” -f “cache_name”;

260多萬面的debris,200格的動態,檔案大小只壓縮在3~4GB,而且在max和maya裡都還拖得動。